
Welcome to the fascinating world of training AI models! Have you ever wondered how these clever machines learn to do what they do? Teaching an AI model seems like entering a complicated and mysterious world. But no fear! AI or artificial intelligence is changing our world in amazing ways and driving progress in many areas. At the heart of all of these advances is machine learning, a part of AI that allows systems to learn and improve using data without the need for special instructions. Training an AI model means giving it data and a special set of instructions called an algorithm. This helps the AI recognize patterns and make predictions. This article explores key concepts of Training of AI models, Discuss basic and advanced concepts you need to learn.
Choosing the right learning algorithm for training AI models
The first step is to choose a suitable one AI learning algorithm based on the type of problem you want to solve. Here’s a breakdown of two common, beginner-friendly algorithms:
Supervised learning
Supervised learning involves labeling the data with the desired output. The algorithm learns this mapping between the input data and the corresponding output. Examples include:
Linear regression for training AI models
Used to predict continuous values (e.g. property prices based on size and location).
Unsupervised learning for training AI models
This approach involves unlabeled data, where the algorithm attempts to uncover hidden structures or patterns in the data. Examples include:
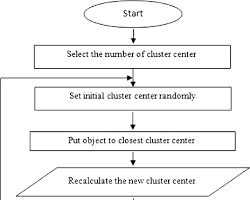
K-means clustering
Groups data points into a predefined number of clusters based on similarities
Thanks to Zen Software for the image
Also Read: Introducing Gemma: Google’s New AI Tool
Common simple learning algorithms
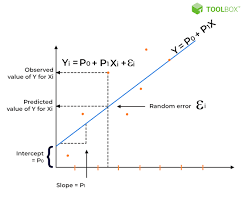
Linear regression
This algorithm finds a linear relationship between input variables (features) and a continuous output variable (target). Linear regression is often used for forecasting and forecasting tasks.
K-Nearest Neighbors (KNN)
KNN classifies data points based on their proximity to their K nearest neighbors in the training data. It is a versatile algorithm, but can be computationally intensive for large data sets.
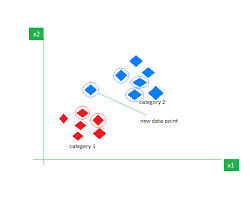
Figure: Thanks to Researchgate
Decision trees
Decision trees are similar to a flowchart, where each internal node represents a test for an attribute and each leaf node represents a classification or prediction. They are interpretable, meaning you can understand the decision-making process behind the model’s predictions.
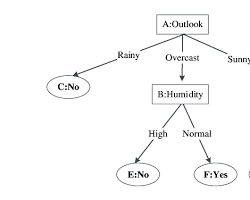
Figure: Thanks to Toolbox
K-means clustering
This algorithm groups data points into K clusters, thereby minimizing the sum of the squared distances between points and their cluster centers. K-Means is suitable for customer segmentation and anomaly detection.
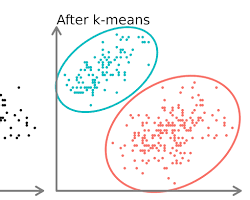
Thanks to Wikipedia for the image
Principal component analysis (PCA)
PCA identifies the principal components that explain the most variance in the data. It is widely used for dimensionality reduction and data visualization.
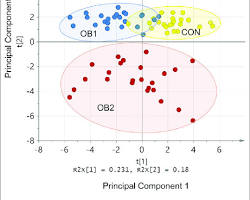
Image from Toolbox
Data preparation
After selecting the algorithm, it is important to prepare your data for training. This means the following:
Data collection
Collect a data set relevant to your task. Make sure it is representative of the real-world scenario you want to model.
Data cleaning
Fix missing values, inconsistencies and errors in your data. This can include techniques such as imputation, outlier removal, and data transformation.
Data splitting
Divide your dataset into training, validation and test sets. The training set is used to train the model, the validation set is used to fine-tune hyperparameters (parameters that control the behavior of the algorithm), and the test set is used to evaluate the performance of the model on unseen data.
Also read: VMware Private AI: A new departure in generative AI for enterprises
Training the model
Here is a step-by-step guide Training of AI models:
Import libraries
Use libraries like NumPy, Pandas, and Sci-Kit-Learn (popular Python libraries for AI and machine learning) in your programming environment.
Loading data
Import your prepared dataset into your code.
Define the model
Instantiate the selected algorithm (e.g. LinearRegression or KMeans) from the appropriate library.
Train the model
Fit the model to the training data. The algorithm learns the underlying patterns or relationships within the data.
Fine-tuning hyperparameters (optional)
If necessary, adjust hyperparameters to optimize the performance of the model. Techniques such as grid search or random search can be used.
Evaluation and refinement
After training, it is important to assess the effectiveness of the model:
Evaluate for validation set
Use the validation set to measure the performance of the model on unseen data. Metrics such as mean square error (MSE) for regression or accuracy for classification can be used.
Refine the model
If performance is unsatisfactory, consider the following:
- Collecting more data.
- Try another algorithm.
- Further optimize hyperparameters.
- Using regularization techniques to prevent overfitting (the model memorizes the training data too well and cannot generalize to new data).
Diploma
The world of AI may seem vast and complicated, but mastering the art of training AI models with simple learning algorithms is within reach. By embracing the core principles discussed in this guide, you’ll be well-equipped to confidently embark on your own AI adventures.
By following these steps and understanding the core concepts of Training of AI models With simple learning algorithms, you have laid the foundation for exploring more complex machine learning techniques. Remember that effective training is an iterative process. Experiment, evaluate and refine your approach to build robust and accurate AI models. As you progress, consider moving into deeper learning architectures like neural networks for even more complex tasks.
FAQs
What are simple learning algorithms in AI training?
Simple learning algorithms in AI model training are basic instruction sets that enable an AI model to learn from data without overly complex processes. These algorithms are designed to be easy to understand and implement, making them ideal for beginners in AI training.
Do I need previous programming knowledge to train an AI model with simple learning algorithms?
While some programming knowledge can be helpful, it is not always necessary to have prior knowledge. Many simple learning algorithms in AI training can be implemented using easy-to-use tools and platforms, requiring only a basic understanding of programming concepts.
How do I choose the right simple learning algorithm for my AI model?
Choosing the right simple learning algorithm depends on factors such as the type of data you are working with, the problem you are trying to solve, and your expertise. It is important to research different algorithms and their capabilities to determine which one best suits your needs.
Can I train complex AI models with simple learning algorithms?
While simple learning algorithms may not be suitable for training highly complex AI models, they can still be effective for a variety of tasks. By combining several simple algorithms or incorporating them into more advanced techniques, you can often achieve impressive results without the need for overly complicated methods.